Almost every organization present on one of the three Microsoft clouds (Azure, M365, Dynamics 365) utilizes Azure AD Conditional Access policies. This lengthy blog post is for everyone that works with Conditional Access policies. No matter your role will extend your knowledge to make proper decisions when you design your conditional access policies.
Even if you already have a Conditional Access policy design or implemented one, you will find this article useful and adjust some of your practices. In this article, I do not recommend which policies you should apply. You will learn how to take a step back and think about the whole process, not just about the policies themselves.
I divided the blog post into four sections (Plan, Design, Build, Operate). It is crucial to read every section of it and follow them in order during your project. Implementing Conditional Access policies is so easy that almost anyone can do it. But when you start messing around, things can get complicated. That is why skipping any project phase is not an option.
Throughout the article, I use the CA abbreviation for Conditional Access.
Plan
Every project starts with a plan. I know it sounds like a cliché, but having a plan is critical when you start designing CA policies. This plan can help you to make proper decisions and sometimes can save your day as well.
- Right people for the right work
You need to involve the correct people that will work, participate and make decisions in this project. I’ve seen many examples where organizations implemented the CA policies ad-hoc because the IT department got an order to do so. But this approach most of the time can lead to disruption. Depends on the policy scope, you need to involve your architects (cloud, security, network), engineers, CISO, support desk, etc.
- Gather requirements
Once you have good people around you, you will need to collect and document their requirements. Everyone can share their opinion, and putting that on paper is crucial for you. You will need these requirements to make your design. You can have conditions that can be conflicting with each other. These conditions can cause one or the other department to have an impact. That is why for you, as an owner of the CA policies design, it is critical to understand, document, and guide the rest of the organization during this process that will achieve everyone’s goals. Later on, in another blog post, I will show you an example of how you can use the requirements and translate them into the design.
- Build your Pilot program
During this stage of the project, you will organize pilot groups to test each planned policy. It is critical to choose your pilot groups accurately. I’ve seen many bad examples where organizations will pilot solutions within their IT organization, and once the pilot is successful, they will continue rolling out throughout the organization. This approach is deficient and has a lot of potential for failure. You can’t test some scenarios within the IT organization. Imagine that you have an application used only within the HR department, and you want to protect it using CA policies. In this case, piloting within the IT organization will give you negative observation.
Instead, what I recommend is to build an organization-wide pilot program. Inform your organization about your internal testing program and let them subscribe to it. You want to keep your participants enthusiastic about your pilot projects. For example, you can establish an award system, where every quarter in a lottery, they can win cool gadgets (headphones, phone, tablet, etc.) Collecting participant’s reactions is equally relevant. You can gather their comments through an internal survey system. It is essential to communicate with this group honestly, on time, and be present when they need help and support as best as you can. Otherwise can lead to many frustrations, and people will avoid being members of this group no matter the prize. :) You can use this pilot group of people for many other projects.
Design
- Start with the highest scope.
When you design CA policies, it is essential to detect similarities from the documented requirements. By similarities, I mean policies that you can apply to a full scope of users or applications. It is crucial to start from the higher scopes, and then create granular policies targeting smaller scope. Policies that you can apply to the whole organization is an example ( Enforce MFA registration for all users or Block legacy authentication for all users and all applications). These example policies apply to all users or applications in the organization. Once you cover the highest scopes, you can think about individual cases. You can as well categorize your users or applications based on similar criteria within your organization. You can create personas like Developers, Management, C-Level, Administrative employees, Departments, etc. For the applications, you can create categories like High, Medium, or Low sensitive applications. You can use as well Internal or External facing applications.
- Minimize the number of policies
If you want to simplify your design and do not have an ample amount of policies, you need to start with the highest scope or grouping first. I’ve seen many organizations with a massive amount of policies, and because of this, they become unmanageable even unpredictable. The worse case I’ve seen is an organization with 126 CA policies. After a redesign, we reduced the policy number to 18 only. If you can achieve the same results with less, then it is better. :) Of course, the number depends as well on the size of the organization. But I firmly believe that if you have more than 20-30 CA policies, you are doing something wrong, and you should go back to the drawing board.
- Build Rings for testing policies
I hope you a familiar with the Microsoft Windows as a Service update strategy. If you are not, you can read more details about it. But this strategy is not the topic of our blog post. Instead, we are going to use a similar approach to push our CA policies into production. The picture below shows how Microsoft is deploying Windows 10 Windows as a Service in separate Rings.
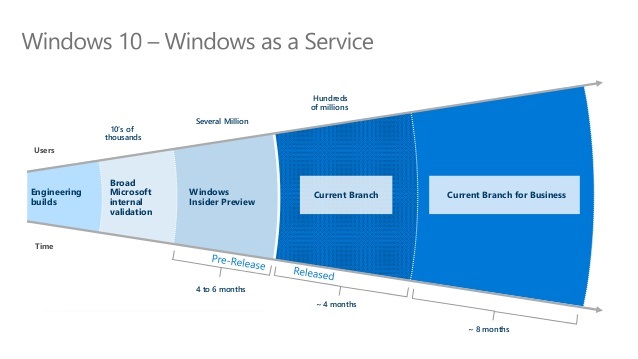
The strategy here is to organize your pilot participants in Ring groups (Azure AD Cloud groups) to test your policies. So, design a couple of Rings, preferably not more than three. Of course, this depends on the size of your organization, but don’t overcomplicate. Once you design your deployment rings and inform pilot participants, you can use this Windows as a service idea to push the policies into production. You start with Ring 1 (a small set of users throughout the organization) to test your CA policy. Further, based on the outcome (telemetry and survey results) you proceed with extensive scope in Ring 2, Ring 3, and as a final step, you deploy to all users in production. Now you have a mechanism that will give you an idea of how the policies are working in your organization, do you have an impact, and if you do, it is easy to roll back with just removing the Ring group from the policy scope.
- Standardize your naming convention
When you have a considerable amount of policies naming conventions will be critical. A standardized naming convention will help you detect which policy is in production, the correct scope, the action, etc. When you dig inside Azure AD sign-in logs, it will be beneficial to have a good naming convention. From the policy name, you can identify why the policy applies or what should be the outcome. As long as you have a good naming convention that works for you, there is no poor choice. Microsoft has documentation with some naming convention proposal, but I extend this to my own.
Naming convention structure and example for the production policy:
| T/P- | Control- | for- | Principal- | Cloud_App- | when- | Conditions |
|---|---|---|---|---|---|---|
| P- | Require_MFA- | for- | All_Users- | All_Apps | when- | on-External-network |
| P- | Block_Legacy_Auth- | for- | All_Users- | All_Apps |
Naming convention structure and example during the Ring implementation:
| T/P- | Control- | for- | Principal- | Cloud_App- | when- | Conditions |
|---|---|---|---|---|---|---|
| T- | Block_Legacy_Auth- | for- | R1- | All_Apps | ||
| T- | Block_Legacy_Auth- | for- | R2- | All_Apps | ||
| T- | Block_Legacy_Auth- | for- | R3- | All_Apps |
Explanation:
| Structure | Description |
|---|---|
| T/P | Test, Production |
| Control | Block, Allow, Require configured control |
| Principal | All or Single User(s), Individual or Ring group (R1,R2), Azure AD Role |
| Cloud_App | All or individual application(s) |
| Conditions | (optional) If there are conditions specified like network, platform etc. |
I saw many examples where names contain version numbers, but I’m not in favor of this. Keep the versioning in your code repository. I do not see a reason why you would have the same policy different version applied. If the scope or control changed, then you need to create a new name.
- Plan your exclusions carefully
It was easy to lock down your access to the tenant in the past. These days thanks to the redesigned UI, it is difficult but not impossible. That is why it is critical to exclude the Emergency Break glass accounts from all block policies.
If you don’t know what Emergency Break glass accounts are, check this documentation.
Of course, the only exception here is the Block legacy authentication policy, which should apply to the Break glass accounts as well. Many organizations use groups to exclude break glass accounts from CA policies, but I’m not in favor of this approach. Using groups brings extra dependency on the exclusions, and that is group management privileges. If a user can get permission to modify group membership, that is potentially an option to exclude himself from CA policies too. To avoid this situation, I would rather exclude two break glass accounts individually instead of as members of a group. Group exclusions can work when you have a big list of policy exceptions because you identified a problem. Group exclusion can work too, when you still use service accounts, and you need to exclude them from policies.
Note: Be aware that anyone who has the rights to modify the group membership can make exclusions from the policy. This way can be potential for misuse, and because of this, you should monitor group membership changes.
- Design for disruption
Disruption in cloud services sometimes can be a domino effect. That is why it is essential to design for disruption. In the past, we faced challenges to satisfy the MFA or network requirements in our policies. And interruptions do not always depend on Azure services. Apple or Android notification services can be down, Azure SMS or call providers can have disruption. Even your network (company internet or VPN) that is a requirement in policies can be unavailable. Because of all these corner cases, you need to design your CA policies for disruption. That means creating emergency access policies that you can activate in case of a disturbance. You will keep these policies disabled by default, but using the Emergency break glass accounts, can enable them to avoid end-user impact. In the case of MFA or network interruption, you enable CA policy that will skip this requirement, and your organization can continue working. You enable the emergency CA policy only during major service interruptions, not small hiccups that the provider will resolve within minutes. These policies have a unique prefix “EMERGENCY” in their name.
Build
Finally, once you put all this on paper, have a good plan and design, it is time to start implementing it. As a general rule, you should never enable CA policies directly to the whole organization from the beginning.
- What-If tool as your friend
You should always start testing policies with the What-If tool and simulate the impact on your organization.
Note: You need to be aware that What-If evaluates only the enabled (On) or enabled in (Report only) policies. In this case, if you want to use the tool on a smaller user scope, I would recommend to scope the CA policy to one test user and simulate the results for that test user to see the outcome before you go to the next step.
- Always implement using the Ring strategy
You don’t want to implement policies that can have a bad end-user experience and destruct your project. Bad end-user experience can be a blocker of the project. Especially when you hit the C level in your organization, and they feel the awful user experience themselves. This approach can lead to frustrations and poor decisions. It is your responsibility to turn your end-users into advocates of your project. That is why in the design phase, I recommended building a Ring implementation strategy. Using the Ring methodology will lower the risk of disruption. If you decide to follow the Ring implementation strategy, you need to be sure that your process will get slower but at least will be robust. Implementing a policy in a specific Ring will require waiting at least a week to proceed further. On the other hand, using this approach, you make sure that policies that you implemented in production are bulletproof.
- Feedback and log data are your gold
To collect feedback you can use two techniques. One is to organize a survey. You can use Microsoft Forms, which comes for free for every M365 customer. Ask your pilot users to provide their observations not just about technical challenges but as well about their experience. The other technique is to collect telemetry data from the AAD logs and analyze it. I would suggest using both in combination. Why? You want to know what is happening in the backend (from the logs), but at the same time, you want to recognize the user experience. If something is looking satisfactory at the backend (policies properly applied and working) does not mean the user experience is acceptable too. I firmly believe that when you implement security measures, people need to understand your point and have a good experience. This way, you will get their support in the next policy implementation or future project.
Telemetry data and dashboards that will present your rings can help you to spot problems early, even sometimes before the users. Spotting problems in your dashboard will play a considerable part in this phase. Once you spot an issue, you can react with a rollback or fix your policy, and end-users don’t suffer. Using this approach, they will even more appreciate your effort because they will feel your support and flexibility to help immediately. Do not forget the communication and support for these pilot groups from the Planning phase. Once the telemetry data and the user’s reaction are positive, you can move forward to the next ring or pushing the policy to all users with confidence.
Operate
Many organizations are ignoring this critical phase. Once implementation is over, it is crucial to manage and operate this solution as well. I’ve seen many examples where people want to show me their policies, and they wonder who created the rest of the policies, why policies are changed and not configured as they thought, etc.
- Delegate rights
This challenge brings the RBAC to the table. It is critical to have control over who can create, modify, delete CA policies. You don’t want everyone being able to change your configuration, nor adding exceptions to your policy. A good start is using the Azure AD built-in role “Conditional Access Administrator”. This role will allow you to limit the users who can manage CA policies. I highly recommend you to use this role via PIM and with an approval process. This way will make sure that no-one will abuse the responsibilities and modify your policies.
- Good visibility
Every change should be controlled and properly planned. The CA policy changes will be logged in the Azure AD audit logs. You need to keep these logs for a longer period so you can have full visibility. By default, Azure AD keeps the audit logs for 30 days only.
Once you transfer your sign-in and audit logs to your Log Analytics workspace, you can analyze the CA policies using the built-in Conditional Access Insights Workbook. You can implement your custom workbooks as well. Notify your admins if someone performed an unauthorized adjustment.
- Configuration as a Code
CA policies are critical for protecting your cloud. Keep the management and monitoring tight and have control a hundred percent of the time. If you are serious about Infrastructure as Code, you can use M365 DSC for keeping your policies as code. This way, you can keep your CA configuration in the desired state. If you detect changes, you can audit or overwrite them. You can investigate more about Microsoft365DSC by going to the Microsoft365DSC GitHub page.
Business Continuity and Disaster Recovery (BCDR)
Disruption can happen and will happen for sure. The problem is that Murphy always kicks in when you do not plan. When we discuss business continuity and disaster recovery, you need to be aware that this is a shared responsibility between Microsoft and you. Microsoft will take care of the service availability and disaster recovery, and you need to take care of your part (backing up your CA policies).
It is critical to pay attention to this stage because there is no undo button when you modify policies. Microsoft doesn’t perform a backup of your policy configuration as well. Therefore you can’t call Microsoft and ask them to restore the backup from yesterday. :)
I visit organizations daily, and I must say that almost 90% of them do not have any procedure for backing up their CA policy configuration. I’ve seen many backup examples like word documents with screenshots, excel files with configuration settings, and many other options. I do not say that this is wrong, but it can be very inflexible, especially when you need to change any of those or restore all of them. Keeping these files up to date rarely happens. There are many community efforts to create solutions for CA policy documentation, and my preference is code. :)
Therefore I suggest documenting all CA policies as code. And all changes that you perform always should go via code. This way will give you the opportunity even in the worse situations when by accident someone deletes all the policies with just one click to recreate/re-enable all of them. The code approach will help with the Ring structure as well. The actual implementation steps will come in another blog post.
Summary
I hope you found this lengthy article valuable, you learned something, and it gave a new perspective to your Conditional Access project. Leave your comments below and share the word further using the share buttons.